
A new era of storage: Open compute with RISC-V and memory fabrics
February 21, 2018
Story

In the last few years, we have witnessed a massive change in how data is generated, processed and further leveraged to garner additional value and intelligence.
In the last few years, we have witnessed a massive change in how data is generated, processed, and further leveraged to garner additional value and intelligence, all influenced by the emergence of new computational models based on deep learning and neural network applications. This profound change started in the data center where deep learning techniques were used to offer insights into vast data volumes, mostly to classify and/or recognize images, enable natural language or speech processing, or understand, generate, or successfully learn how to play complex strategy games. The change has also brought a wave of more power-efficient compute devices (based on GP-GPUs and FPGAs) created specifically for these classes of problems, and later included fully customized ASICs, further accelerating and increasing the compute capabilities of these deep learning-based systems.
Big Data and Fast Data
Big Data applications use specialty GP-GPU, FPGA and ASIC processors to analyze large datasets with deep learning techniques, and unmask trends, patterns, and associations, enabling image recognition, speech recognition, among others. As such, Big Data is based on information largely from the past, or rested data that typically resides in a cloud. A frequent outcome of a Big Data analysis is a “trained” neural network capable of executing a specific task, such as recognizing and tagging all faces in an image or video sequence. Voice recognition also demonstrates the power of the neural network.
The task is best executed by specialized engines (or inference engines), which reside directly on the edge device and led by a Fast Data application (Figure 1). By processing data captured locally at the edge, Fast Data leverages algorithms derived from Big Data to provide real-time decisions and results. As Big Data provides insights derived from ‘what happened’ to ‘what will likely happen’ (predictive analysis), Fast Data delivers real-time actions that can improve business decisions, operations, and reduce inefficiencies, invariably affecting bottom line results. These methods may apply to a variety of edge and storage devices, such as cameras, smartphones and SSDs.
Compute on data
The new workloads are based on two scenarios: (1) training the large neural network on a specific workload, such as image or voice recognition; and (2) applying the trained (or ‘fitted’) neural network on edge devices. Both workloads require massive parallel data processing that includes the multiplication and convolution of large matrices. Optimal implementations of these compute functions require vector instructions that operate on large vectors or data arrays. RISC-V is an architecture and ecosystem well-suited for this type of application as it offers a standardization process supported by open source software that enable developers complete freedom to adopt, modify or even add proprietary vector instructions. Prominent RISC-V compute architecture opportunities are outlined in Figure 1.
Move data
The emergence of Fast Data and computations at the edge creates a factual consequence that moving all of the data back and forth to the cloud for computational analysis is not very efficient. First, it involves relatively large data latency transfers at long distances across the mobile network and Ethernet, which is not optimal for the image or speech recognition apps that MUST operate in real time. Second, computing at the edge allows for more scalable architectures, where image and speech processing, or in-memory compute operations on SSDs can be executed in a scalable fashion. As such, each added edge device brings an incremental increase in the computational power required. Optimization on how and when the data moves is a key factor in the scalability of new architectures.
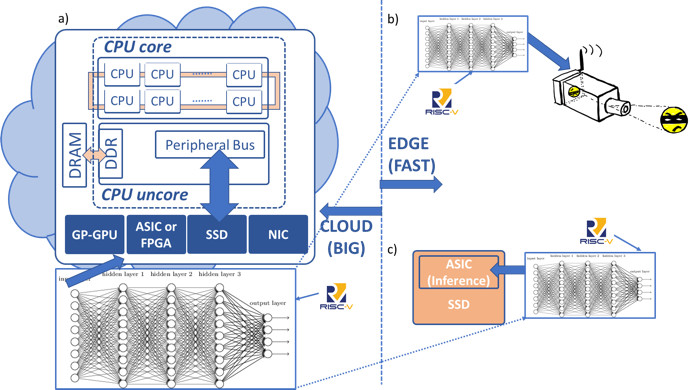
Another similar, and important trend in how data is moved and accessed exists on the Big Data side and in the Cloud (Figure 2). The traditional computer architecture (Figure 2a) utilizes a slow peripheral bus that attaches to a number of other devices (e.g. dedicated machine learning accelerators, graphics cards, fast SSDs, smart networking controllers, etc.). The slow bus affects device utilization by limiting the communications capabilities between themselves, the main CPU, and main, potentially persistent memory. It is also not possible for this new class of computational devices to share memory amongst themselves, or with the main CPU, which results in wasteful and limited data movement across a slow bus.
There are several important industry trends emerging on how to improve data movement between different compute devices, such as the CPU and compute and network accelerators, as well as how the data is accessed in memory or fast storage. These new trends are focused on open standardization efforts that deliver faster, lower latency serial fabrics, and smarter logical protocols, enabling coherent access to shared memory.
Next generation data-centric computing
Future architectures will need to deploy open interfaces to persistent memory and cache-coherency-enabled fast busses (e.g. TileLink, RapidIO, OpenCAPI, and Gen-Z) that connect to compute accelerators, to not only improve performance substantially, but enable all devices to share memory and reduce unnecessary data movement.
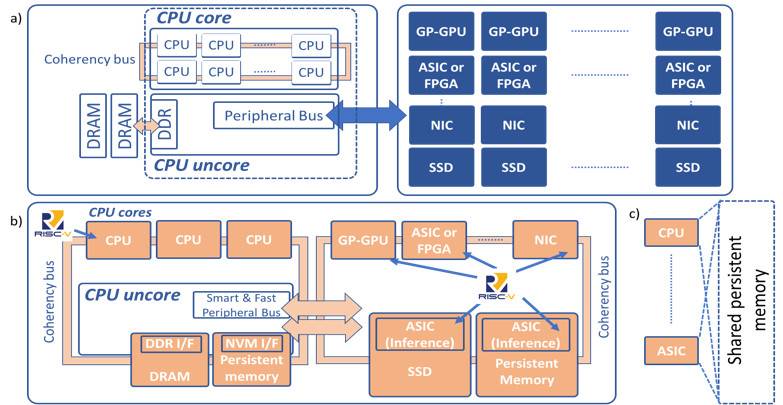
The role of the CPU uncore and network interface controllers will grow as the key enablers for moving data. The CPU uncore component will have to support key memory and persistent memory interfaces (e.g. NVDIMM-P), as well as memory that resides close to the CPU. Smart and fast busses for compute accelerators, smart networking and remote persistent memory will also need to be implemented. Any device on the bus (e.g. CPUs, general-purpose or purpose-built compute accelerators, network adapters, storage or memory) can include their own compute resources with the ability to access shared memory (Figures 2b and 2c).
To optimize data movement, RISC-V technology can be the key enabler as it will implement vector instructions for new machine learning workloads on all of the compute accelerator devices. It enables open source CPU technologies that support open memory and smart bus interfaces, and implements a new data-centric architecture with coherently shared memory.
Solving the challenges with RISC-V
Big Data and Fast Data pose future data movement challenges, paving the way for the RISC-V instruction set architecture (ISA), and its open, modular approach, ideally suited to serve as the foundation for data-centric compute architectures. It provides the ability to:
- Scale compute resources for edge compute devices
- Add new instructions, such as vector instructions for key machine learning workloads
- Locate small compute cores very close to storage and memory media
- Enable new compute paradigms and modular chip designs
- Enable new data-centric architectures where all of the processing elements can coherently access shared persistent memory, optimizing data movement
The RISC-V is developed by a membership of over one hundred organizations and includes a collaborative community of software and hardware innovators who can adapt the ISA to a specific purpose or project. Anyone who joins the organization can design, manufacture and/or sell RISC-V chips and software under a Berkeley Software Distribution (BSD) license.
Final thoughts
To realize its value and possibilities, data needs to captured, preserved, accessed, and transformed to its full potential. Environments with Big Data and Fast Data applications have exceeded the processing capabilities of general-purpose compute architectures. The extreme data-centric applications of tomorrow require purpose-built processing that supports independent scaling of data resources in an open manner.
Having a common open computer architecture centered on data stored in persistent memory, while allowing all devices to play a compute role, is a key enabler of these new scalable architectures driven by a new class of machine learning compute workloads. The next-generation of applications across all cloud and edge segments will need this new class of low-energy processing, as specialty compute acceleration processors focus on the task at hand, reducing wasted time moving data, or performing excess computing that is not relevant to the data. People, communities and our planet thrives through the power, potential and possibilities of data.



